Configure automated evaluations for your GenAI application spans using Evaluator Rules. Learn to map evaluators to span data, define application rules, and manage backfill configuration.
Evaluator Rules define how automated evaluations are applied to your application’s spans. They connect evaluators (LLM-based or rule-based functions) with span data, specify what inputs to use, and determine which spans qualify for evaluation.
Evaluator Rules provide the configuration layer between your evaluators and your application’s telemetry data. When properly configured, they automatically assess the quality, safety, and performance of your GenAI application based on real-time span data.
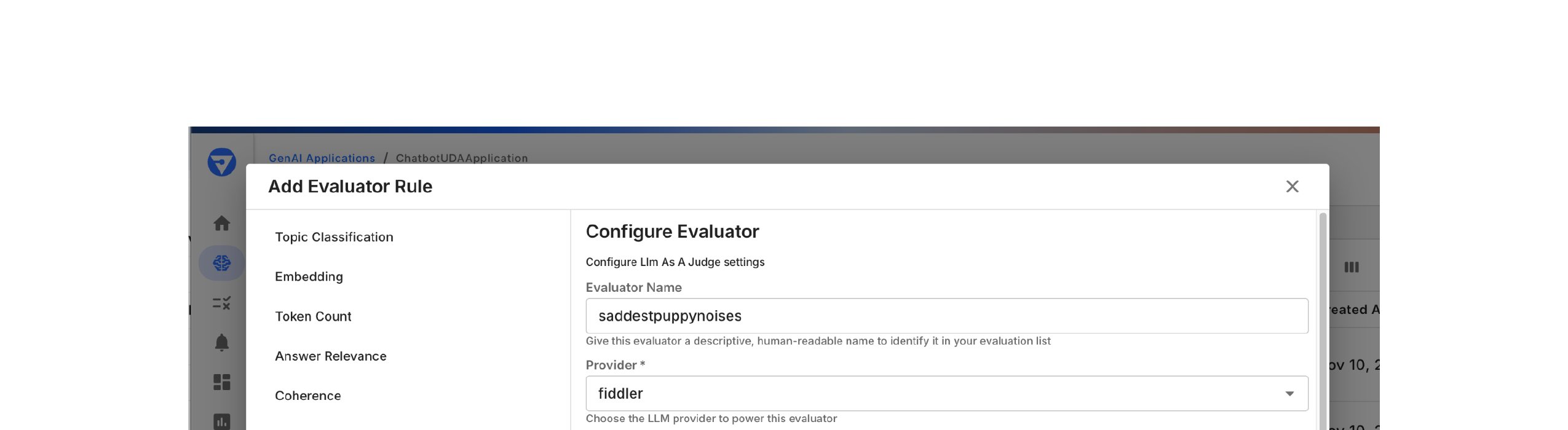
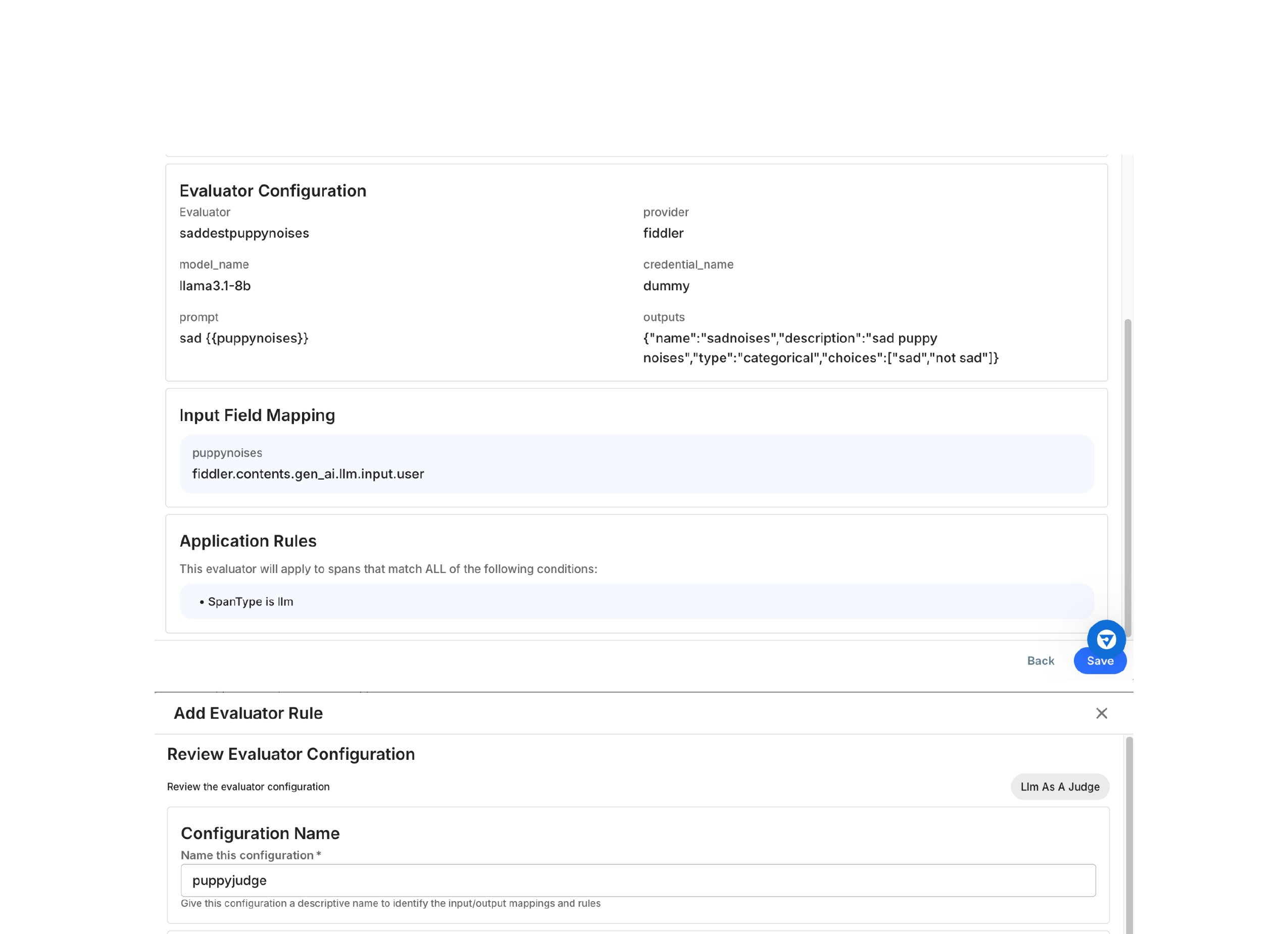
An Evaluator is a configured model or function that performs analysis over spans. It can classify, score, or assess the quality of data generated by your application.Evaluators are defined by:
Provider - The LLM provider (OpenAI, Anthropic, Gemini, Fiddler)
Model - The specific model to use for evaluation
Credentials - Authentication to the provider (configured via LLM Gateway)
Prompt or Logic - The evaluation instructions or function
Note: Evaluators are defined at the organization level and shared across all projects in your organization.
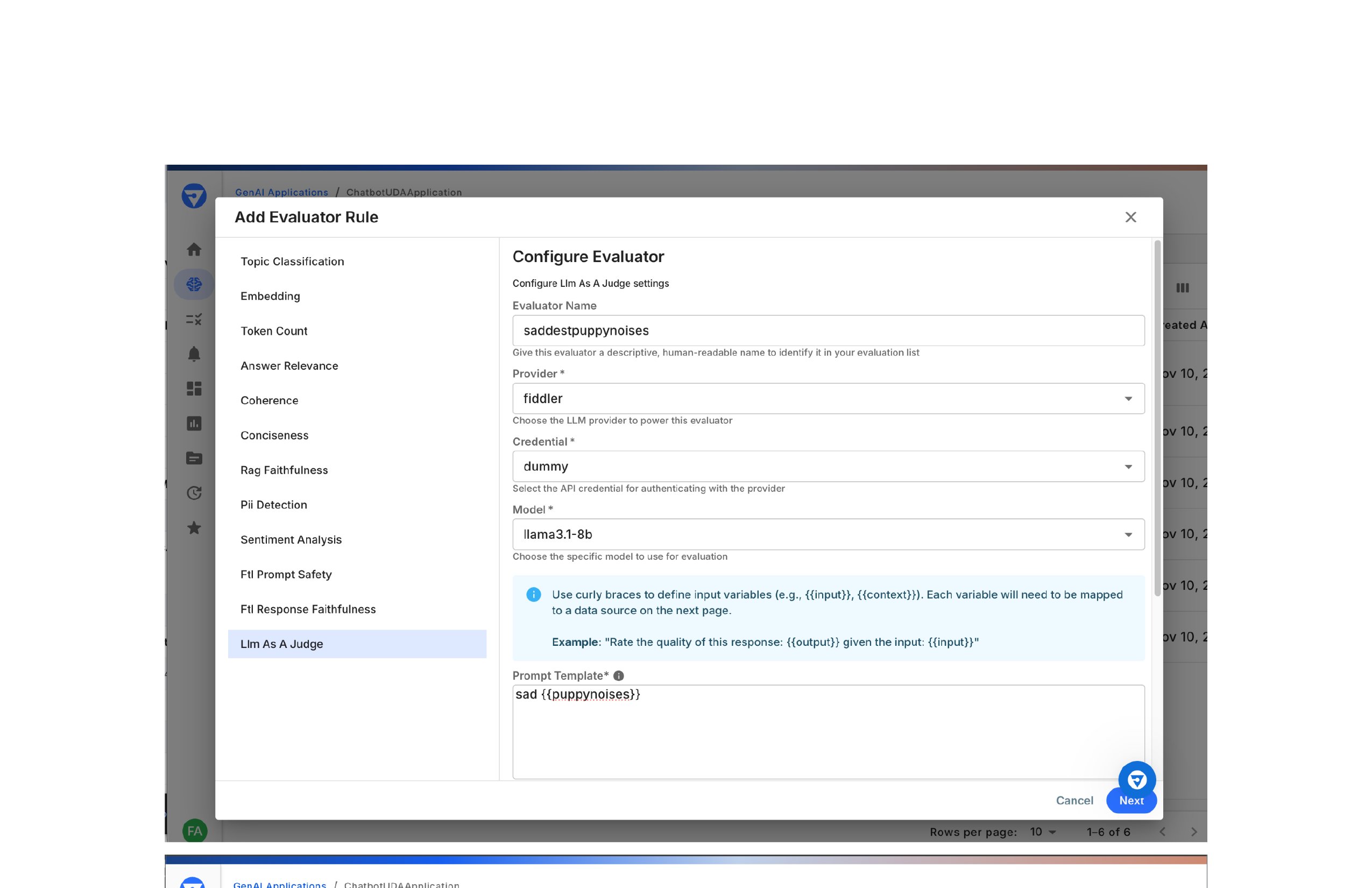
Input Mappings define how data flows from spans into evaluators. Each variable used in an evaluator’s prompt (such as {{input}} or {{context}}) must be mapped to a field or attribute in the span data.For example, if your evaluator prompt includes {{puppynoises}}, you must map that variable to a span attribute like fiddler.contents.gen_ai.llm.input.user.
Backfill controls whether evaluations apply retroactively to existing historical data or only to spans created after the rule is configured.
The backfill process runtime depends on the volume of data in your history. Be certain to backfill only as needed.
Backfill respects the rule’s sampling rate. If a rule uses evaluator downsampling, a backfill evaluates the same fraction of traces — and because the sampling decision is deterministic, a backfill at the same rate re-applies the same outcome and skips the same traces. To score traces a downsampled rule skipped, create a new rule (or recreate the rule) with a higher sampling rate and backfill enabled.
Each application supports up to 100 evaluator rules by default. This soft cap keeps evaluation and monitoring performant as the number of rules grows. On self-hosted deployments, an administrator can raise or lower the limit through configuration.When an application reaches the limit, creating another rule returns a 422 error. Delete rules you no longer need to make room.
Note: Deactivating a rule does not free a slot — disabled rules still count toward the limit. Delete unused rules to reduce the count.
Configure evaluator settings including provider, model, prompt, and outputs
Tip: For Fiddler-provided evaluators, the evaluation method and fields are predetermined. You only need to map inputs and configure application rules.
Click Next to continue.
2
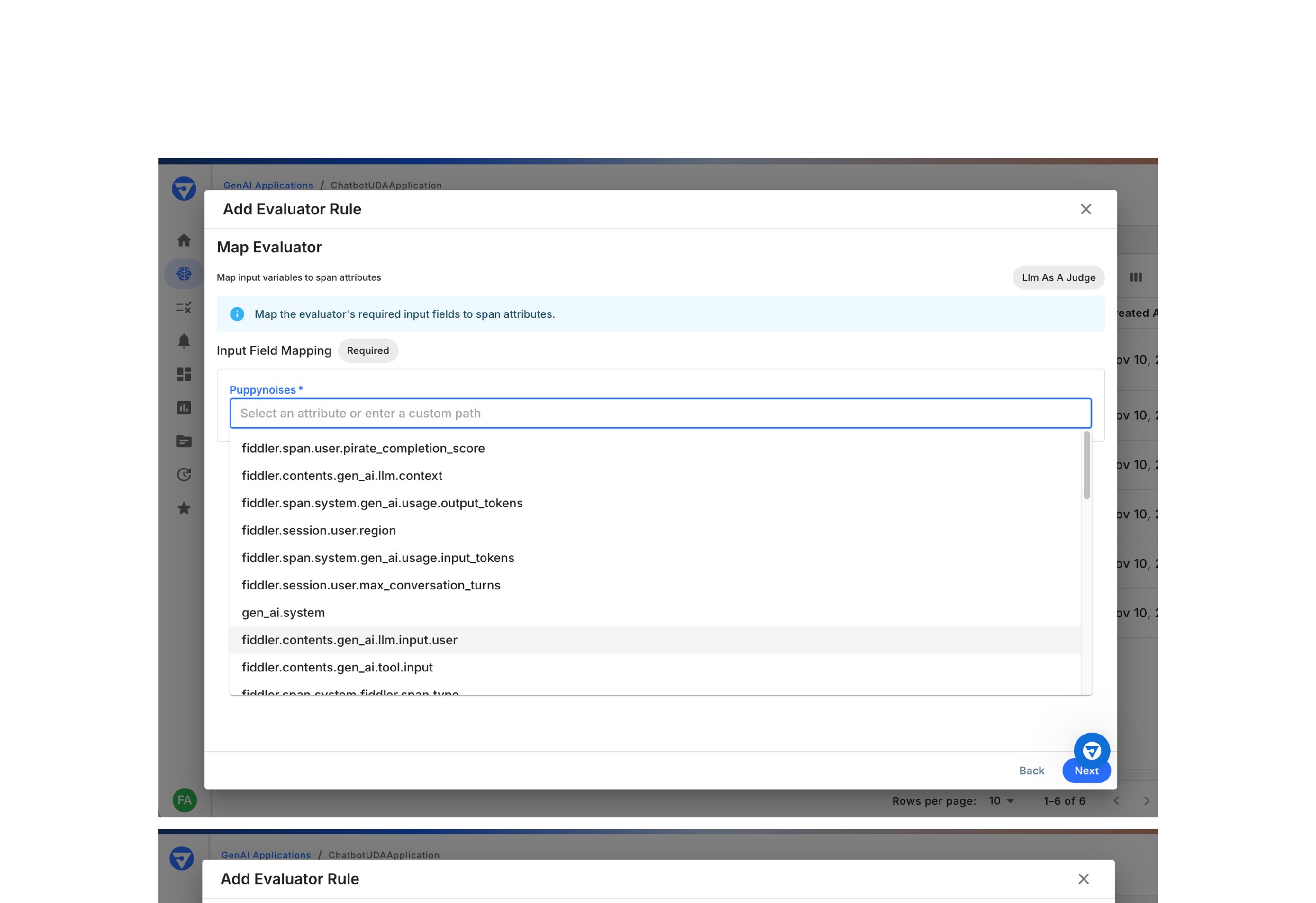
Map Input Fields
Map each evaluator input variable to a span attribute.
In the Map Evaluator step, you’ll see all required input variables
For each variable (e.g., puppynoises):
Click the Select an attribute or enter a custom path dropdown
Choose from available span attributes or enter a custom path manually
Common Span Attributes:
fiddler.span.user.pirate_completion_score
fiddler.contents.gen_ai.llm.context
fiddler.span.system.gen_ai.usage.output_tokens
fiddler.session.user.region
fiddler.span.system.gen_ai.usage.input_tokens
fiddler.session.user.max_conversation_turns
gen_ai.system
fiddler.contents.gen_ai.llm.input.user
fiddler.contents.gen_ai.tool.input
And many more…
Step 2: Map input fields to span data
Repeat for all input variables
Click Next to continue
All required input variables must be mapped. The evaluator cannot run without complete input mappings.
3
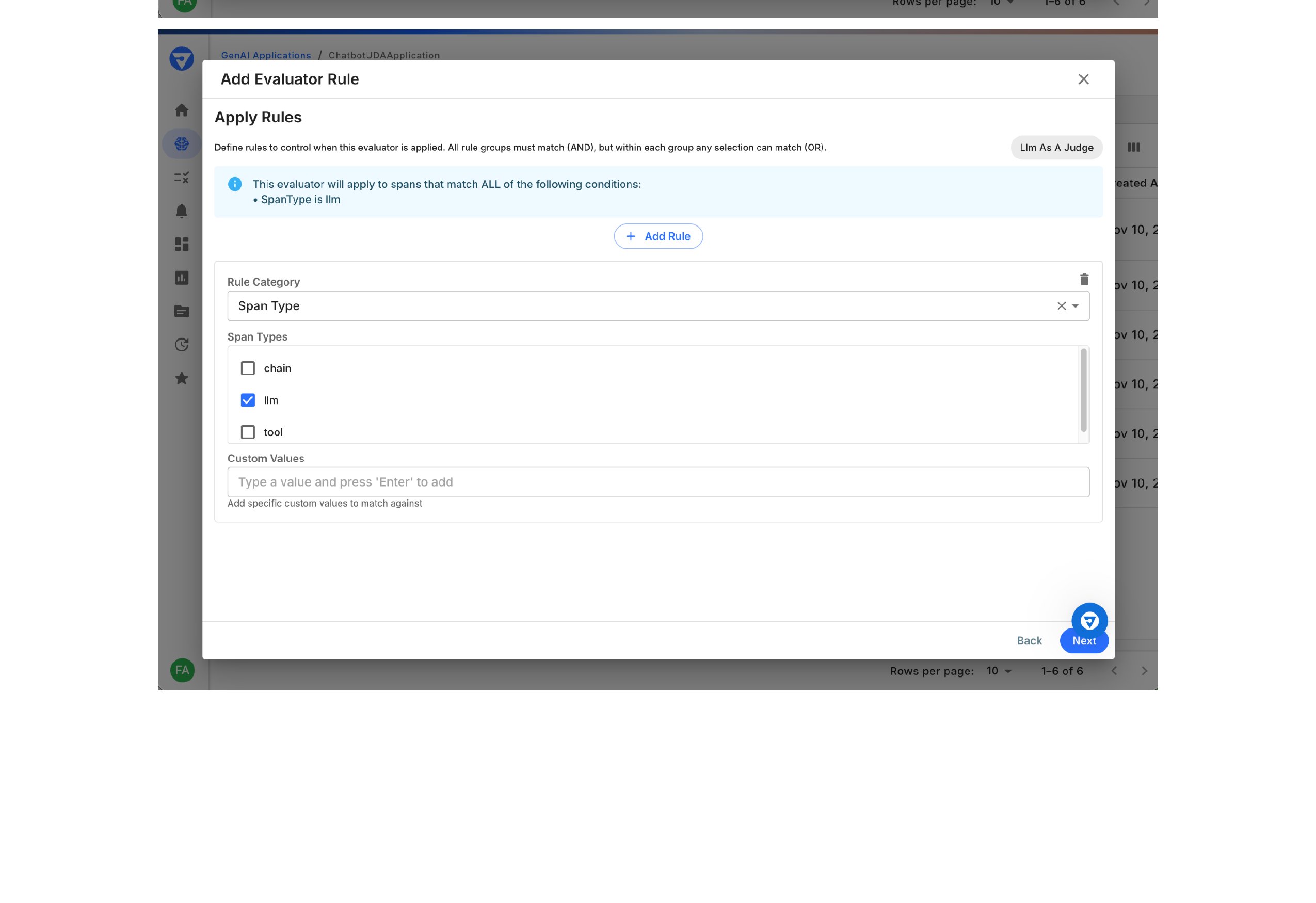
Define Application Rules
Specify which spans to evaluate by setting filter conditions.
In the Apply Rules step, you’ll see the current rule conditions
The info box shows: “This evaluator will apply to spans that match ALL of the following conditions:”
Click Add Rule to add a new condition category
For each rule category:a. Rule Category
Select the attribute type (e.g., Span Type)
b. Values
Choose which values to match:
chain
llm ✓
tool
c. Custom Values
(Optional) Add specific custom values to match
Step 3: Configure application rules
Understanding Rule Logic
AND condition across categories - A span must match ALL rule categories
OR condition within a category - A span can match ANY value within a single category
Example:
Rule 1: SpanType = llmRule 2: Region = us-east OR us-westResult: Evaluates spans that are type "llm" AND in either "us-east" or "us-west"
Add multiple rule categories as needed
Click Next to continue
4
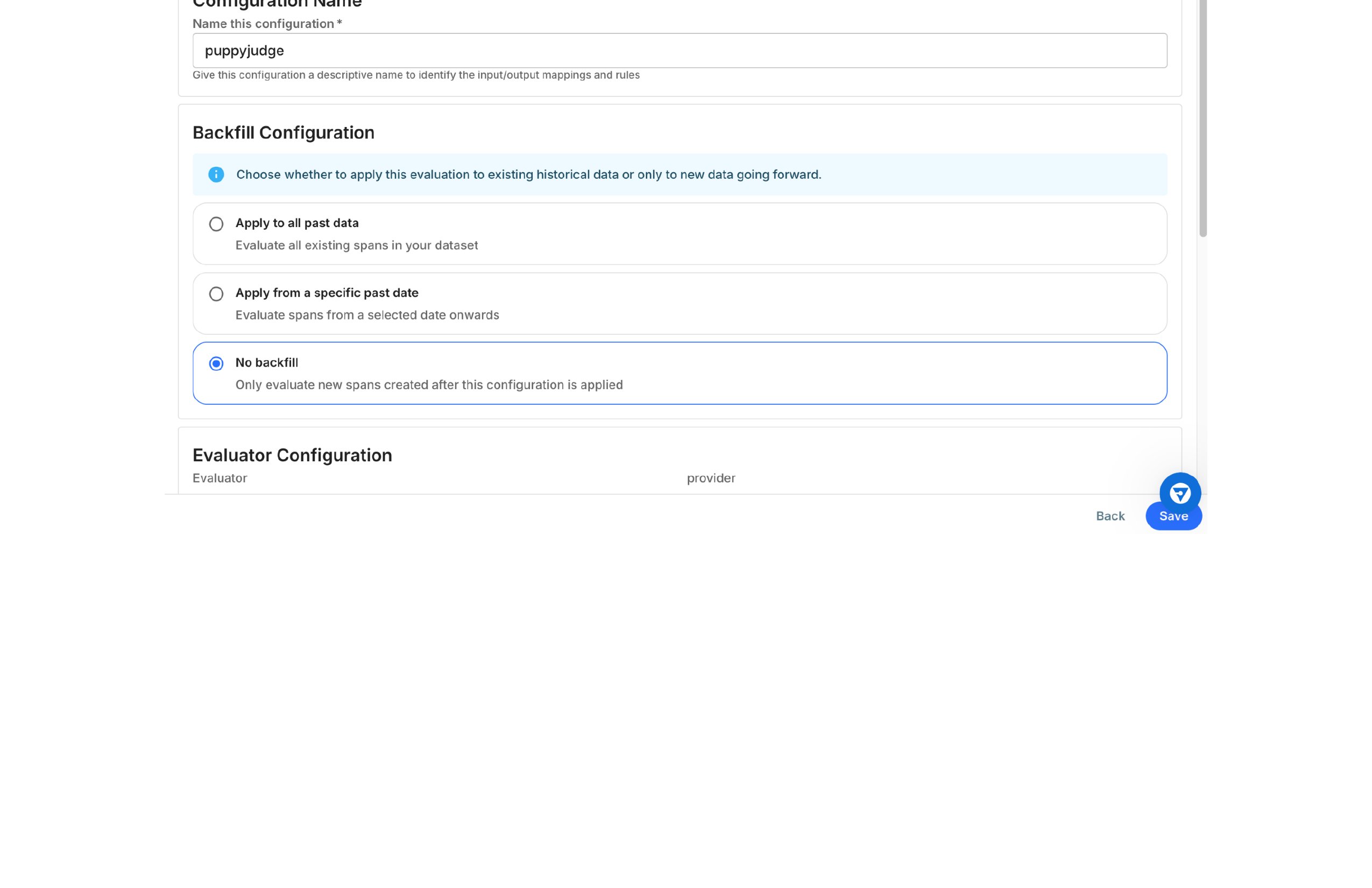
Configure Backfill and Review
Determine whether to apply the evaluator to existing historical data and review your configuration.Backfill ConfigurationChoose one of three options:Option 1: Apply to all past data
Evaluates all existing spans in the dataset
Use when: You need complete historical coverage
Warning: May take significant time for large datasets
Option 2: Apply from a specific past date
Evaluates spans created after a chosen date
Use when: You want partial historical coverage
Select the start date using the date picker
Option 3: No backfill (Default)
Evaluates only new spans created after activation
Use when: You only need a forward-looking evaluation
Best for: Testing new evaluators or reducing processing time
Fraction of matching traces evaluated, shown as a percentage (100% = evaluate everything). Visible when evaluator downsampling is enabled for your deployment.