Project Structure on UI
Supervised machine learning involves identifying a predictive task and building a model using that data. Fiddler captures this workflow with project and model entities.
Projects
A project represents a machine learning task (e.g. predicting house prices, assessing creditworthiness, or detecting fraud).
A project can contain one or more models for the ML task (e.g. LinearRegression-HousePredict, RandomForest-HousePredict).
Create a project by clicking on Projects and then clicking on Add Project.

- Create New Project — A window will pop up where you can enter the project name and click Create. Once the project is created, it will be displayed on the projects page.
You can access your projects from the Projects Page.
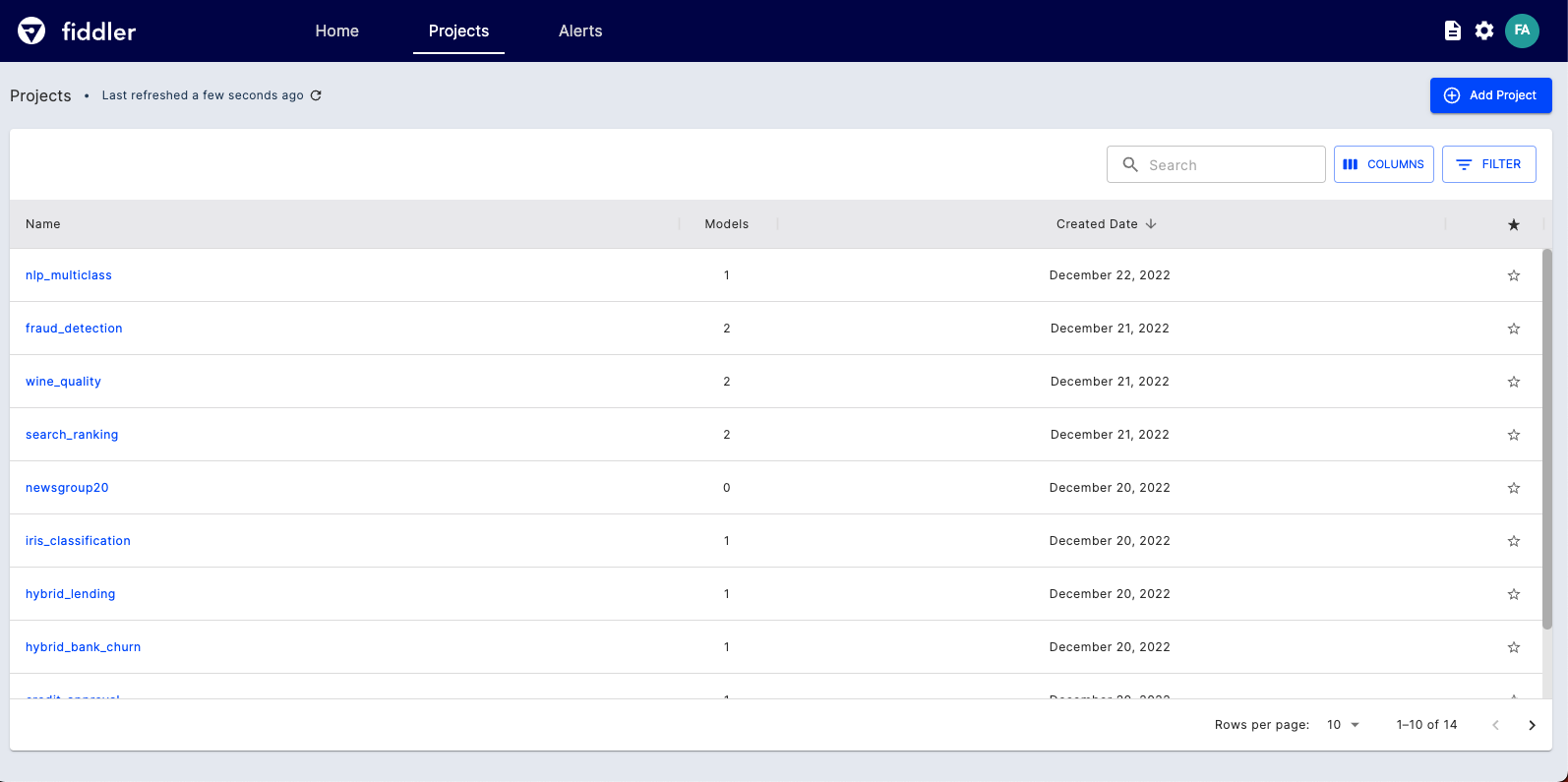
Projects Page on Fiddler UI
Models
A model in Fiddler represents a machine learning model. A project will have one or more models for the ML task (e.g. a project to predict house prices might contain LinearRegression-HousePredict and RandomForest-HousePredict). For further details refer to the Models section in the Platform Guide.

Model Artifacts
At its most basic level, a model in Fiddler is simply a directory that contains model artifacts such as:
- The model file (e.g.
*.pkl) package.py: A wrapper script containing all of the code needed to standardize the execution of the model.


Project Dashboard
You can collate specific visualizations under the Project Dashboard. After visualizations are created using the Model Analytics tool, you can pin them to the dashboard, which can then be shared with others.

↪ Questions? Join our community Slack to talk to a product expert
Updated 9 days ago