> ## Documentation Index
> Fetch the complete documentation index at: https://docs.fiddler.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Semantic Mappings
> How Fiddler maps raw OTel attribute keys to canonical semantic concepts for cross-framework analytics, alerts, and dashboards
## Overview
Fiddler ingests OpenTelemetry traces from a wide range of AI frameworks and SDKs — OTel [GenAI Semantic Conventions](https://github.com/open-telemetry/semantic-conventions-genai), OpenInference (LlamaIndex, LangChain), Vercel AI SDK, Claude Code, LiteLLM, Langfuse, and many more. Each framework uses its own attribute key names for the same underlying concept. For example, the number of input tokens might be sent as `gen_ai.usage.input_tokens` by one framework, `llm.token_count.prompt` by another, and `ai.usage.promptTokens` by a third.
Server-side semantic mappings solve this problem by associating each raw attribute key with a canonical **semantic concept** — a framework-agnostic name like `input_tokens`, `model_name`, or `input`. This enables Fiddler's dashboards, alerts, custom metrics, and evaluators to work consistently across all frameworks without requiring per-framework instrumentation (client-side).
## How It Works
When your application sends OpenTelemetry traces to Fiddler, the raw attribute keys are stored exactly as sent — Fiddler does not transform or rename them. In the backend, Fiddler enables you to map each attribute key to a semantic concept, producing a canonical name alongside the original key.
All downstream features — monitoring charts, alert rules, custom metrics, evaluator input configuration, and the Trace Explorer — use the semantic concept for queries. This means a dashboard showing "average input tokens over time" works identically whether your application uses the OTel GenAI convention (`gen_ai.usage.input_tokens`), the OpenInference convention (`llm.token_count.prompt`), or any other supported framework's naming.
Custom attributes that don't map to any semantic concept are still stored and queryable by their original key name. Semantic mapping only applies to attributes that Fiddler recognizes as carrying a known concept.
## Semantic Concepts
Fiddler defines over 30 semantic concepts, organized into the following categories.
### Token Usage
| Concept | Description |
| ----------------------------- | ---------------------------------------------- |
| `input_tokens` | Number of tokens in the input/prompt |
| `output_tokens` | Number of tokens in the output/completion |
| `total_tokens` | Total token count (input + output) |
| `cache_read_input_tokens` | Cached input tokens read (Claude, GPT caching) |
| `cache_creation_input_tokens` | Cached input tokens created |
| `reasoning_tokens` | Reasoning tokens (o1/o3 models) |
### Cost (Estimated)
| Concept | Description |
| ------------- | ---------------------- |
| `total_cost` | Total LLM usage cost |
| `input_cost` | Input/prompt cost |
| `output_cost` | Output/completion cost |
### Model and Provider
| Concept | Description |
| --------------- | --------------------------------------------------------- |
| `model_name` | LLM model identifier (e.g., `gpt-4.1`, `claude-sonnet-4`) |
| `provider_name` | LLM provider identifier (e.g., `openai`, `anthropic`) |
### Agent and Tool
| Concept | Description |
| ------------------- | -------------------------------- |
| `agent_name` | Agent name |
| `agent_id` | Agent identifier |
| `agent_description` | Agent description |
| `tool_name` | Tool/function name |
| `tool_id` | Tool call identifier |
| `tool_type` | Tool type or category |
| `tool_definitions` | Tool/function schema definitions |
### Session and User
| Concept | Description |
| ------------ | ---------------------------------- |
| `session_id` | Conversation or session identifier |
| `user_id` | End-user identifier |
### Content
| Concept | Description |
| --------------------- | ---------------------------------- |
| `input` | LLM prompt or user input content |
| `output` | LLM completion or response content |
| `system_instructions` | System prompt or instructions |
| `retrieval_context` | RAG retrieval context |
| `tool_input` | Tool call arguments |
| `tool_output` | Tool call results |
### Performance
| Concept | Description |
| --------- | ------------------- |
| `latency` | Span duration |
| `ttft` | Time to first token |
### Span Identity
| Concept | Description |
| ----------- | --------------------------------------------------------- |
| `span_name` | Span name |
| `span_type` | Span type or kind (e.g., `llm`, `tool`, `agent`, `chain`) |
### Metadata
| Concept | Description |
| --------------- | ----------------------- |
| `received_time` | Ingestion timestamp |
| `request_id` | LLM request identifier |
| `response_id` | LLM response identifier |
| `finish_reason` | LLM stop/finish reason |
## Default Mappings
Fiddler ships with **over 140+ pre-configured mappings** covering a dozen AI frameworks and SDKs. If your application uses any of the following frameworks, traces are automatically mapped to semantic concepts with no configuration required:
* **OTel GenAI Semantic Conventions** — the standard OpenTelemetry conventions for generative AI (`gen_ai.usage.*`, `gen_ai.request.*`, `gen_ai.response.*`)
* **OpenInference** — used by LlamaIndex, LangChain, and other frameworks (`llm.token_count.*`, `input.value`, `output.value`)
* **Vercel AI SDK** — (`ai.usage.*`, `ai.prompt`, `ai.response.*`)
* **Claude Code** — (`input_tokens`, `output_tokens`, `user_prompt`, `model`)
* **LiteLLM** — (`gen_ai.cost.*`)
* **Langfuse SDK** — (`langfuse.session.id`, `langfuse.user.id`)
* **Google Agent Development Kit (ADK, part of Gemini Enterprise Agent Platform)** — (`gcp.vertex.agent.*`)
* **LiveKit** — (`lk.input_text`, `lk.response.text`)
* **Genkit** — (`genkit:input`, `genkit:output`)
* **MLflow** — (`mlflow.spanInputs`, `mlflow.spanOutputs`)
* **Traceloop / OpenLLMetry** — (`traceloop.entity.input`, `traceloop.entity.output`)
Many semantic concepts are mapped from multiple frameworks. For example, the `input` concept is mapped from over a dozen different attribute keys across all supported frameworks, so Fiddler can display user prompts regardless of which SDK generated the trace.
## When to Add Custom Mappings
The default mappings cover most common frameworks. You may need to add custom mappings when:
* **Using a framework not in the default list** — if your application uses an AI framework or SDK that Fiddler doesn't ship mappings for, you can add mappings for that framework's attribute keys.
* **Custom instrumentation** — if your application uses proprietary or internal attribute key names that differ from standard OTel conventions.
* **Internal naming conventions** — if your organization has adopted non-standard attribute key naming that you want Fiddler to recognize.
For example, if your application sends `my_framework.prompt_tokens` for input token counts, you can create a mapping from `my_framework.prompt_tokens` to the `input_tokens` semantic concept. After the mapping propagates, all charts, alerts, and metrics that use `input_tokens` will include data from this key.
## Span Types
### Why span type mapping is needed
Each AI framework labels span operations differently. OTel GenAI uses `gen_ai.operation.name` with values like `chat` and `completion`. OpenInference uses `openinference.span.kind` with values like `LLM` and `RETRIEVER`. Vercel AI SDK uses `ai.operationId` with values like `ai.generateText`. Langfuse uses `langfuse.observation.type` with values like `generation`. Without normalization, filtering for "all LLM calls" or "all tool executions" in Fiddler would require knowing every framework's convention.
Fiddler resolves this by automatically normalizing raw span type values into a set of canonical types. When a span is ingested, Fiddler checks its attributes for known span type keys (determined by the semantic mapping for the `span_type` concept), extracts the raw value, lowercases it, and maps it to a canonical type.
### Canonical span types
Fiddler recognizes 10 canonical span types:
| Type | Description |
| ----------- | ------------------------------------------------------- |
| `llm` | LLM inference calls (chat completions, text generation) |
| `tool` | Tool or function executions |
| `agent` | Agent invocations |
| `chain` | Chain or pipeline steps |
| `embedding` | Embedding operations |
| `retriever` | Retrieval operations (RAG) |
| `reranker` | Reranking operations |
| `guardrail` | Guardrail checks |
| `evaluator` | Evaluator runs |
| `span` | Generic span (default for unrecognized values) |
### How span type is inferred
Fiddler checks the following attribute keys to find the span type value:
| Attribute Key | Framework |
| --------------------------- | ------------------------------------- |
| `span_type` | Generic / direct |
| `span.type` | Claude Code |
| `fiddler.span.type` | Fiddler legacy |
| `openinference.span.kind` | OpenInference (LlamaIndex, LangChain) |
| `langfuse.observation.type` | Langfuse SDK |
| `gen_ai.operation.name` | OTel GenAI, LiteLLM, Strands |
| `ai.operationId` | Vercel AI SDK |
| `genkit:metadata:subtype` | Genkit |
Once a raw value is found, it is lowercased and mapped to a canonical type using the table below. If the raw value is not recognized, the span type defaults to `span`.
### Recognized raw values
The following table lists all recognized raw values and the canonical span type they map to. Raw values are case-insensitive (lowercased before lookup).
#### Identity values
These are already canonical and map directly:
| Raw Value | Span Type |
| ----------- | ----------- |
| `llm` | `llm` |
| `tool` | `tool` |
| `agent` | `agent` |
| `chain` | `chain` |
| `embedding` | `embedding` |
| `retriever` | `retriever` |
| `reranker` | `reranker` |
| `guardrail` | `guardrail` |
| `evaluator` | `evaluator` |
| `span` | `span` |
#### OpenInference
| Raw Value | Span Type |
| --------- | --------- |
| `UNKNOWN` | `span` |
| `PROMPT` | `span` |
All other uppercase OpenInference values (`LLM`, `TOOL`, `AGENT`, `CHAIN`, `EMBEDDING`, `RETRIEVER`, `RERANKER`, `GUARDRAIL`) are lowercased and match the identity values above.
#### Claude Code
| Raw Value | Span Type |
| ---------------------- | --------- |
| `interaction` | `agent` |
| `llm_request` | `llm` |
| `tool.blocked_on_user` | `chain` |
| `tool.execution` | `chain` |
#### Langfuse
| Raw Value | Span Type |
| ------------ | --------- |
| `generation` | `llm` |
| `event` | `span` |
#### OTel GenAI / LiteLLM / Strands
| Raw Value | Span Type |
| -------------------------- | ----------- |
| `chat` | `llm` |
| `completion` | `llm` |
| `acompletion` | `llm` |
| `text_completion` | `llm` |
| `atext_completion` | `llm` |
| `responses` | `llm` |
| `aresponses` | `llm` |
| `_aresponses_websocket` | `llm` |
| `anthropic_messages` | `llm` |
| `generate_content` | `llm` |
| `agenerate_content` | `llm` |
| `generate_content_stream` | `llm` |
| `agenerate_content_stream` | `llm` |
| `generate` | `llm` |
| `execute_tool` | `tool` |
| `invoke_agent` | `agent` |
| `create_agent` | `agent` |
| `embeddings` | `embedding` |
| `aembedding` | `embedding` |
#### Genkit
| Raw Value | Span Type |
| ------------------ | ----------- |
| `model` | `llm` |
| `background-model` | `llm` |
| `embedder` | `embedding` |
| `tool.v2` | `tool` |
#### Vercel AI SDK
| Raw Value | Span Type |
| ------------------------------ | ----------- |
| `ai.generateText` | `llm` |
| `ai.generateText.doGenerate` | `llm` |
| `ai.streamText` | `llm` |
| `ai.streamText.doStream` | `llm` |
| `ai.generateObject` | `llm` |
| `ai.generateObject.doGenerate` | `llm` |
| `ai.streamObject` | `llm` |
| `ai.streamObject.doStream` | `llm` |
| `ai.embed` | `embedding` |
| `ai.embed.doEmbed` | `embedding` |
| `ai.embedMany` | `embedding` |
| `ai.embedMany.doEmbed` | `embedding` |
| `ai.toolCall` | `tool` |
### Adding new span type mappings
If your framework uses span type values that Fiddler doesn't recognize (appearing as `span` in the Trace Explorer), contact your Fiddler deployment administrator to add the mapping. New mappings take effect within approximately 5 minutes and apply to all subsequently ingested spans.
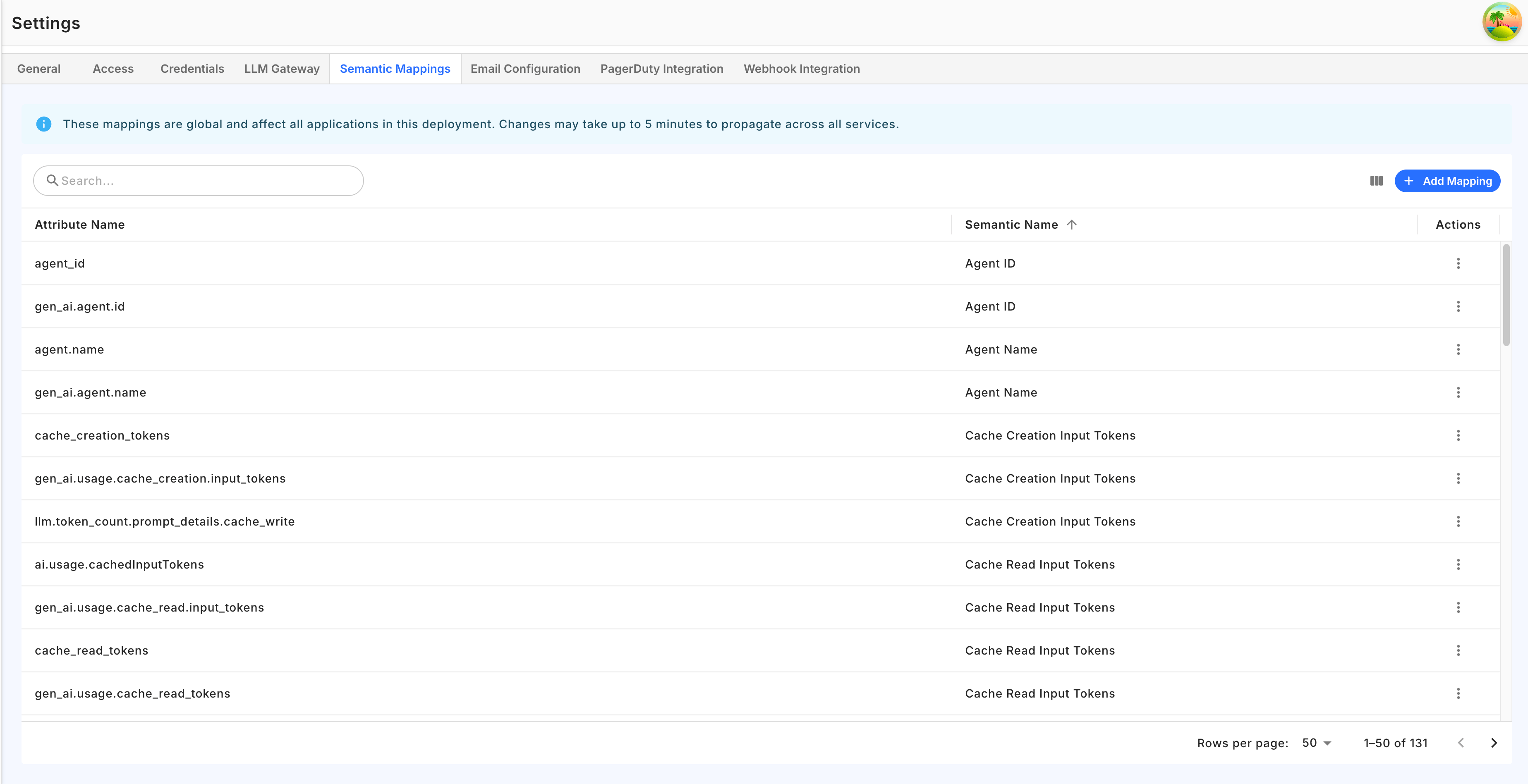
## Managing Mappings via the UI
Semantic mappings are managed from the **Settings > Semantic Mappings** tab in the Fiddler UI.
The tab displays all current mappings in a table with two columns:
* **Attribute Name** — the raw OTel attribute key (e.g., `gen_ai.usage.input_tokens`)
* **Semantic Name** — the canonical concept it maps to (e.g., `input_tokens`)
To add a new mapping:
1. Click the **Add Mapping** button
2. Enter the raw attribute key in the **Attribute Name** field
3. Select the semantic concept from the **Semantic Name** dropdown
4. Click **Add**
To delete a mapping, use the delete action on the mapping row.
Only **Org Admins** can create or delete mappings. All users can view the current mappings.
 ## Propagation
After creating or deleting a mapping, changes take effect within approximately **5 minutes**. Only new spans ingested after the mapping propagates are affected — existing data is not reprocessed.
## Constraints and Limits
| Constraint | Value |
| ---------------------------------- | ------------------------------------ |
| Maximum total mappings | 1,000 |
| Maximum mappings per request | 100 |
| Maximum attribute key length | 256 characters |
| Write rate limit | 10 requests/minute, 100 requests/day |
| Propagation delay | \~5 minutes |
| Required role for write operations | Org Admin |
## Unmapped Attributes
Attributes that don't map to any semantic concept are still fully functional. They are stored with their original key name, appear in the Trace Explorer's span detail view, and are queryable in FQL custom metrics via the `attribute()` function. The only difference is that they won't appear in built-in dashboards or metrics that rely on semantic concepts (such as the token usage chart or the model breakdown view). If you need an unmapped attribute to participate in these features, add a semantic mapping for it.
## Deleting or Changing a Mapping
When you delete a mapping or remap an attribute key to a different semantic concept, the change only affects new spans ingested after the mapping propagates (\~5 minutes). Existing data retains the semantic name that was assigned at ingestion time and is not reprocessed. This means:
* **Deleting a mapping** — new spans with that attribute key will no longer have a semantic name assigned. The attribute is still stored and queryable by its original key, but it stops appearing in concept-based dashboards and metrics.
* **Remapping to a different concept** — new spans will use the new semantic concept. Older spans will continue to use the previous concept. During the transition period, both old and new data are independently queryable.
## Propagation
After creating or deleting a mapping, changes take effect within approximately **5 minutes**. Only new spans ingested after the mapping propagates are affected — existing data is not reprocessed.
## Constraints and Limits
| Constraint | Value |
| ---------------------------------- | ------------------------------------ |
| Maximum total mappings | 1,000 |
| Maximum mappings per request | 100 |
| Maximum attribute key length | 256 characters |
| Write rate limit | 10 requests/minute, 100 requests/day |
| Propagation delay | \~5 minutes |
| Required role for write operations | Org Admin |
## Unmapped Attributes
Attributes that don't map to any semantic concept are still fully functional. They are stored with their original key name, appear in the Trace Explorer's span detail view, and are queryable in FQL custom metrics via the `attribute()` function. The only difference is that they won't appear in built-in dashboards or metrics that rely on semantic concepts (such as the token usage chart or the model breakdown view). If you need an unmapped attribute to participate in these features, add a semantic mapping for it.
## Deleting or Changing a Mapping
When you delete a mapping or remap an attribute key to a different semantic concept, the change only affects new spans ingested after the mapping propagates (\~5 minutes). Existing data retains the semantic name that was assigned at ingestion time and is not reprocessed. This means:
* **Deleting a mapping** — new spans with that attribute key will no longer have a semantic name assigned. The attribute is still stored and queryable by its original key, but it stops appearing in concept-based dashboards and metrics.
* **Remapping to a different concept** — new spans will use the new semantic concept. Older spans will continue to use the previous concept. During the transition period, both old and new data are independently queryable.